
استنساخ الصوت بالذكاء الاصطناعي
ارفع عيّنة صوتية، انسخها بالذكاء الاصطناعي، واحصل على كلام يشبه المتحدث الأصلي. عدة محركات صوتية متاحة. رصيد مجاني عند التسجيل.
ما يمكنك فعله باستنساخ الصوت بالذكاء الاصطناعي

انسخ أي صوت من عيّنة قصيرة
سجّل بضع ثوانٍ من الكلام أو ارفع ملفاً صوتياً موجوداً. يحلل الذكاء الاصطناعي خصائص الصوت — النبرة والإيقاع وطبقة الصوت — ويُنشئ ملفاً صوتياً قابلاً لإعادة الاستخدام. يدعم كل من MiniMax وElevenLabs الاستنساخ الفوري من عيّنة واحدة. يعمل تقليل الضوضاء تلقائياً لتنظيف المدخلات.
أنتج تعليقات صوتية وسرداً
بعد إنشاء صوت مستنسخ، اكتب أي نص واحصل على مقطع صوتي بذلك الصوت. استخدمه لسرد الفيديو أو مقدمات البودكاست أو المحتوى التعليمي أو عروض المنتجات. اضبط السرعة والطبقة والمشاعر حسب السياق. الناتج بصيغة MP3 مع تحميل فوري.

تحدّث بأي لغة بصوتك الخاص
محركات تحويل النص إلى كلام — MiniMax وElevenLabs وGemini TTS — يدعم كل منها عدة لغات. أنتج كلاماً بلغات مختلفة باستخدام ملف صوتك المستنسخ. مفيد لصنّاع المحتوى الذين يُنتجون لجمهور في مناطق متعددة.
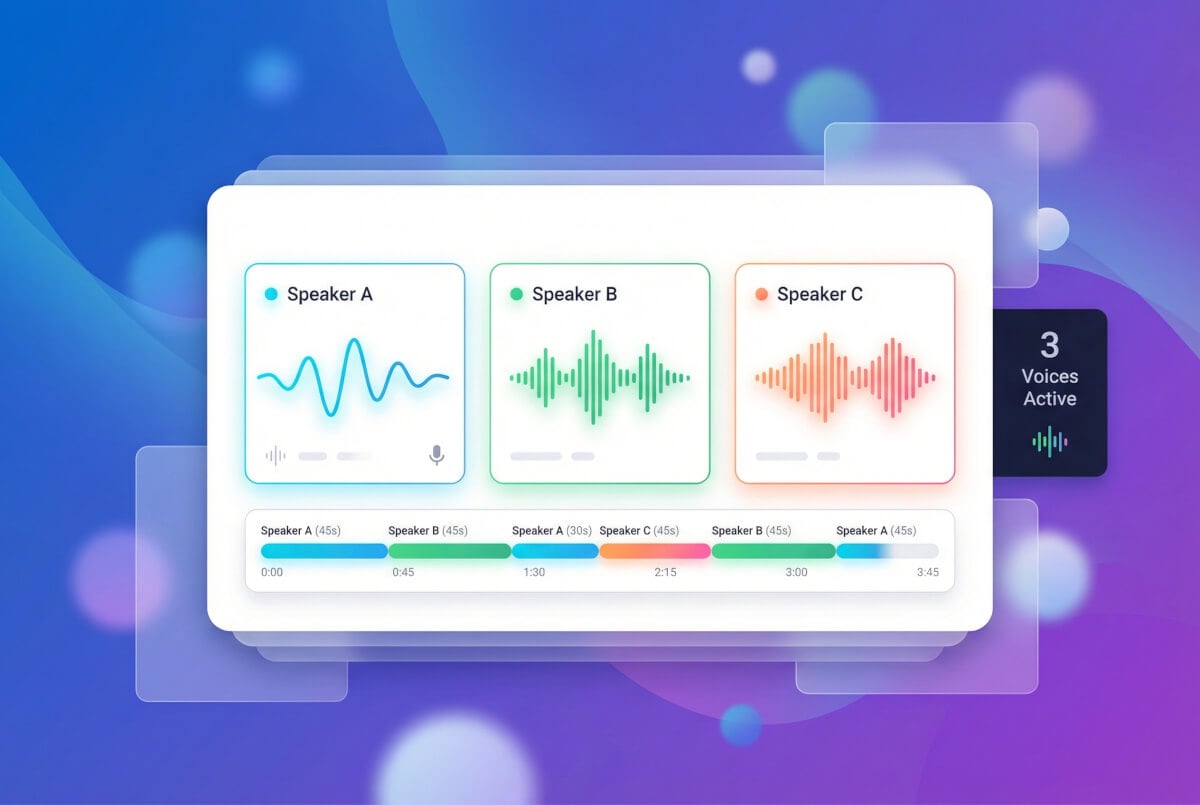
أنشئ حوارات بأصوات متعددة
انسخ عدة أصوات وعيّن كلاً منها لمتحدث مختلف في النص. يمنح نظام المتحدثين المتعددين كل صوت معرّفه الخاص، مما يتيح بناء حوارات أو محتوى بأسلوب المقابلات أو سرد كتب مسموعة بشخصيات مختلفة. معايير كل متحدث — السرعة والطبقة والثبات — مستقلة.
كيف يعمل — ثلاث خطوات

ارفع عيّنة صوتية
قدّم ملفاً صوتياً للصوت الذي تريد استنساخه. بضع ثوانٍ من الكلام الواضح تكفي. يطبّق النظام تقليل الضوضاء وتسوية الصوت تلقائياً.
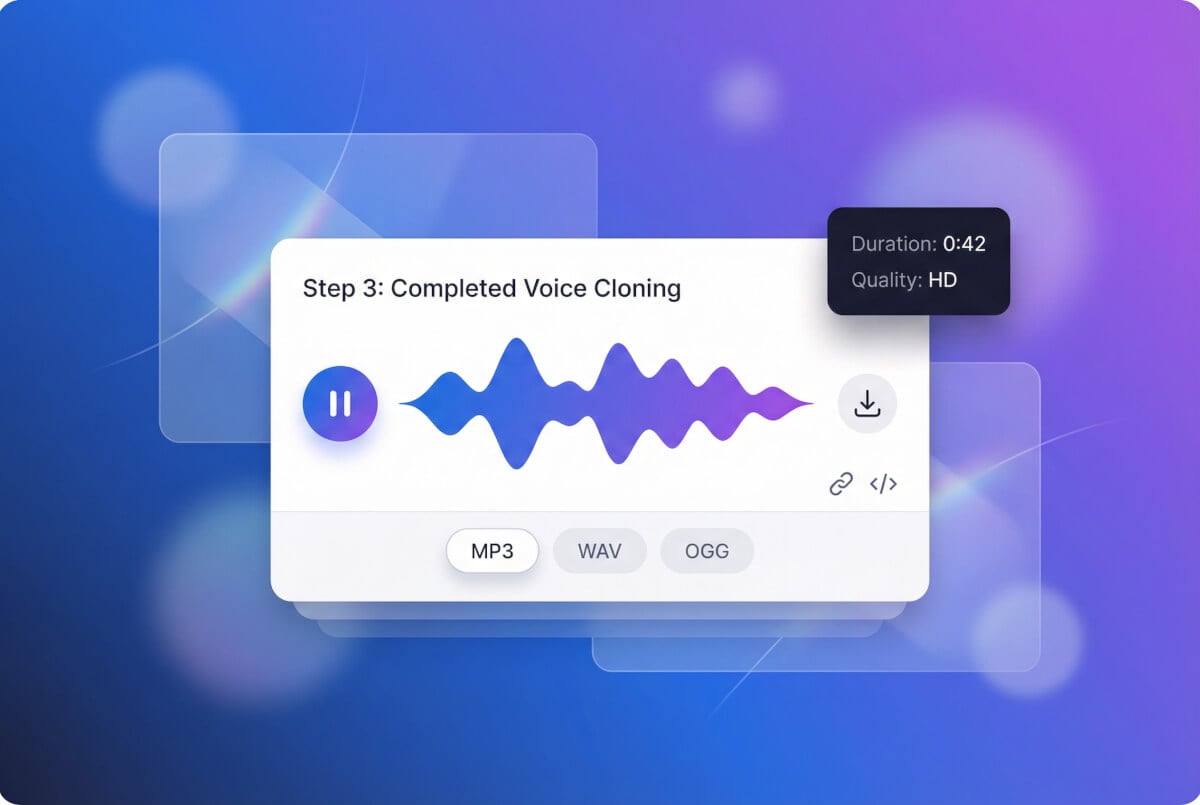
الذكاء الاصطناعي يُنشئ ملفك الصوتي
محرك الاستنساخ — MiniMax أو ElevenLabs — يعالج عيّنتك وينتج معرّف صوت مخصصاً. يلتقط هذا المعرّف الخصائص الصوتية الفريدة للمتحدث ويمكن إعادة استخدامه عبر جلسات مختلفة.
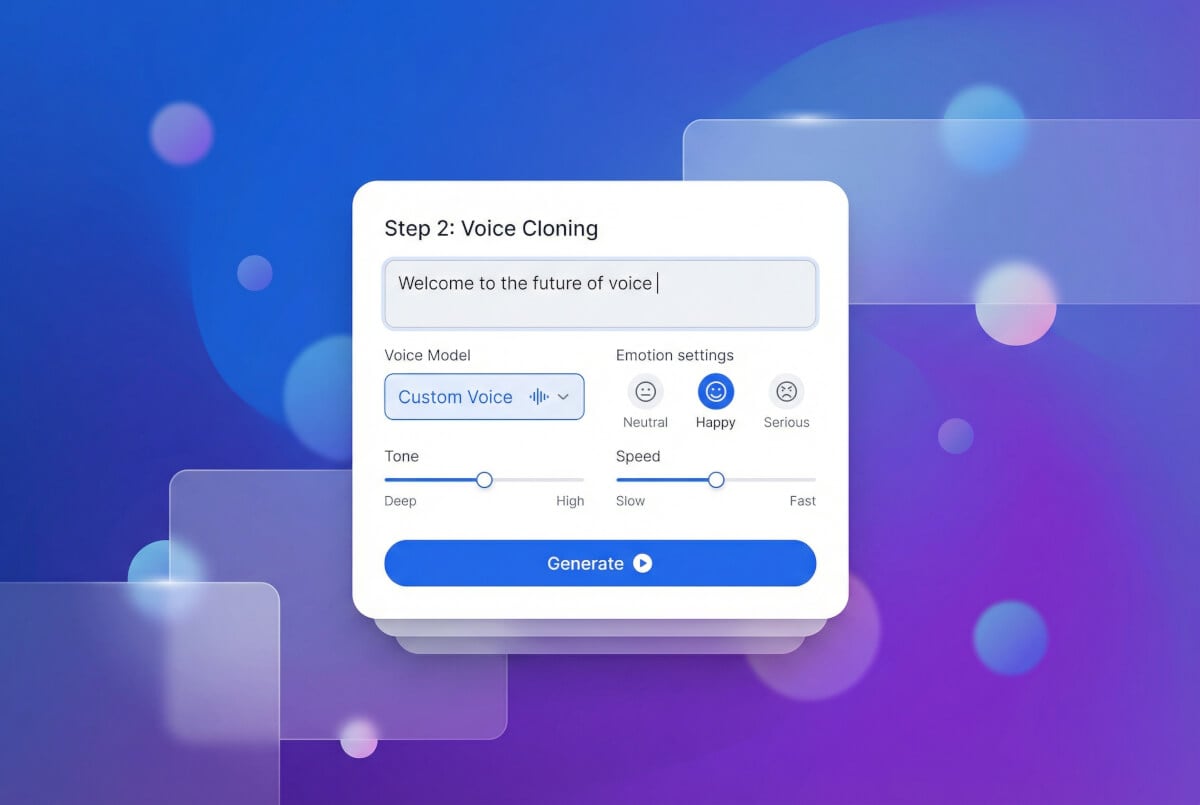
اكتب نصاً واحصل على كلام
أدخل أي نص وسيقرأه الصوت المستنسخ. اضبط السرعة والطبقة والمشاعر والثبات. حمّل النتيجة بصيغة MP3. أعد التوليد بإعدادات مختلفة حتى تحصل على النتيجة المطلوبة.
الأسئلة الشائعة
كيف يعمل استنساخ الصوت بالذكاء الاصطناعي؟
تُقدّم عيّنة صوتية للصوت المستهدف. يحلل نموذج الذكاء الاصطناعي الخصائص الصوتية وينشئ ملفاً صوتياً (معرّف صوت مخصص). عندما تكتب نصاً، يستخدم محرك تحويل النص إلى كلام هذا الملف لتوليد كلام يطابق صوت المتحدث الأصلي.
ما صيغ الصوت المدعومة وما المدة المطلوبة للعيّنة؟
يُدعم MP3 وWAV وM4A. الحد الأدنى بضع ثوانٍ من الكلام الواضح. العيّنات الأطول قد تحسّن الدقة، لكن النظام يطبّق تقليل الضوضاء والتسوية تلقائياً، لذا حتى التسجيلات غير المثالية تعمل. يدعم ElevenLabs أيضاً ملفات عيّنات متعددة لنتائج أدق.
هل استنساخ الصوت مجاني؟
تحصل على رصيد مجاني عند إنشاء حساب. يغطي هذا الرصيد استنساخ الصوت وتوليد الكلام. النظام يعمل بالأرصدة — الاستهلاك يعتمد على النموذج وطول المخرجات. تحقق من رصيدك في حسابك.
ما اللغات المدعومة؟
تدعم محركات تحويل النص إلى كلام عدة لغات. يمكنك استنساخ صوت من لغة وتوليد كلام بلغات أخرى. يتعامل كل من MiniMax وElevenLabs وGemini TTS مع مجموعته الخاصة من اللغات.
ما الفرق بين استنساخ الصوت وتحويل النص إلى كلام العادي؟
تحويل النص إلى كلام العادي يستخدم أصواتاً مُعدّة مسبقاً ومدمجة في النموذج. استنساخ الصوت يُنشئ ملفاً صوتياً جديداً من عيّنتك الصوتية، فيبدو الناتج كشخص محدد وليس كصوت اصطناعي عام. كما يمكنك ضبط معايير مثل الطبقة والسرعة والمشاعر على الأصوات المستنسخة.
هل بياناتي الصوتية آمنة؟
تُعالَج العيّنات الصوتية لإنشاء معرّف صوتي وتُستخدم لتوليد مخرجات الكلام. لا تستخدم المنصة بياناتك الصوتية لتدريب نماذج عامة. لتفاصيل التعامل مع البيانات، راجع سياسة الخصوصية.