
AI 聲音克隆
上傳一段語音樣本,AI 即可分析並複製說話者的聲音特徵,用克隆出的聲音朗讀任何文字。支援 MiniMax、ElevenLabs 等多種引擎。註冊即送免費額度。
聲音克隆能做什麼

從短音訊複製任何聲音
錄製幾秒鐘的語音,或上傳現有音訊檔案。AI 會分析聲音的音色、節奏、音高等特徵,建立可重複使用的語音設定檔。MiniMax 和 ElevenLabs 都支援從單一樣本即時克隆。系統自動進行降噪處理,在克隆前清理輸入音訊。
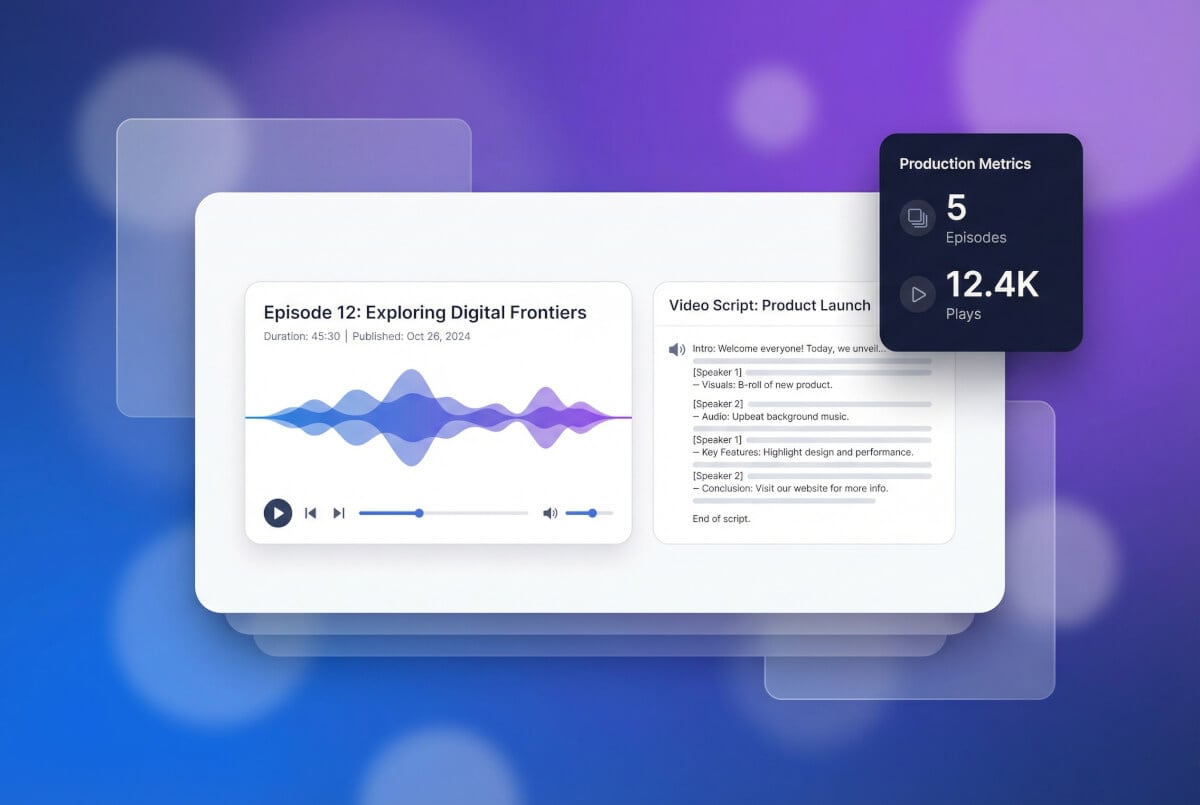
生成配音與旁白
建立克隆語音後,輸入任何文字即可取得該聲音的音訊。可用於影片旁白、Podcast 片頭、教學內容或產品示範。調整語速、音高和情緒參數以符合內容需求。輸出為 MP3 格式,可即時下載。

用自己的聲音說多種語言
聲音克隆背後的 TTS 引擎(MiniMax、ElevenLabs、Gemini TTS)各自原生支援多種語言。你可以用克隆的語音設定檔生成不同語言的語音。適合面向多個地區製作內容的創作者。
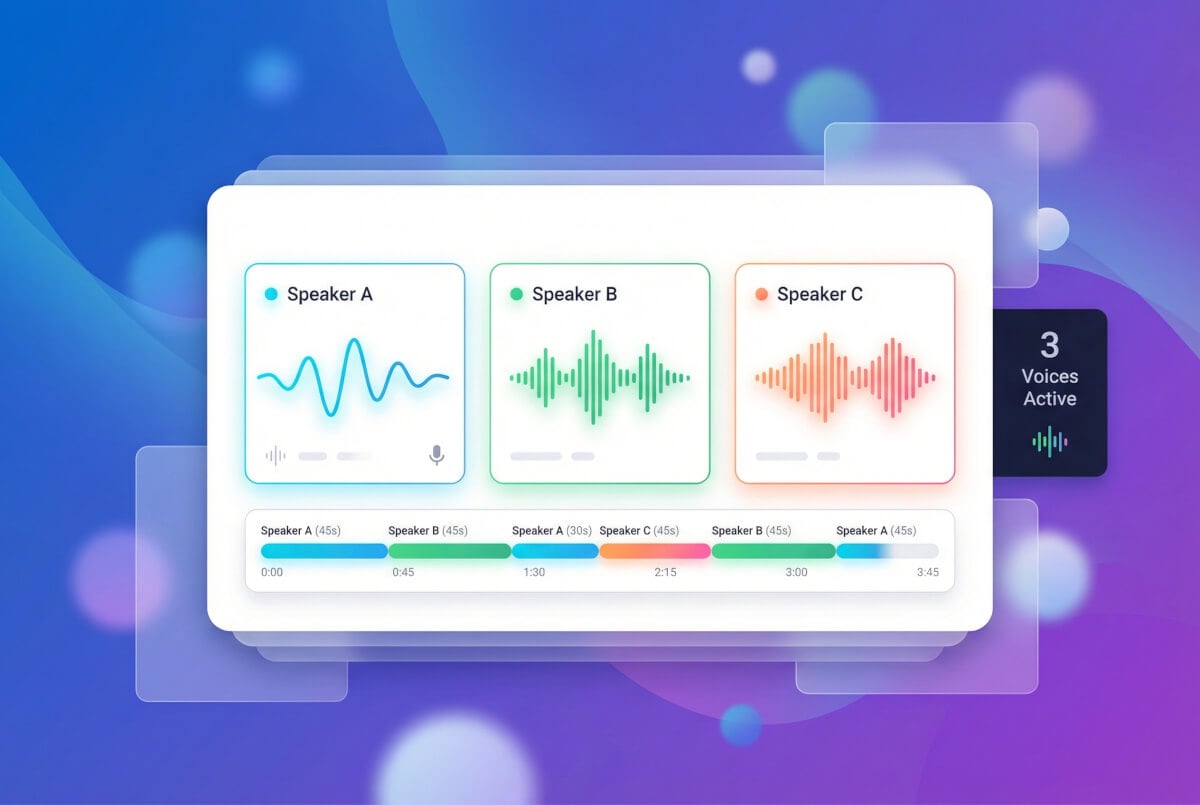
用多種聲音建構對話
克隆多個聲音並分配給腳本中的不同說話者。多講者系統為每個聲音分配獨立 ID,讓你建構對話內容、訪談形式或有聲書旁白,每個角色都有獨特的聲音。每位說話者的語速、音高、穩定性參數各自獨立。
使用流程 — 三個步驟

上傳語音樣本
準備要克隆的聲音音訊檔案。幾秒鐘清晰的語音即可。系統會自動進行降噪和音量標準化,確保輸入信號乾淨。
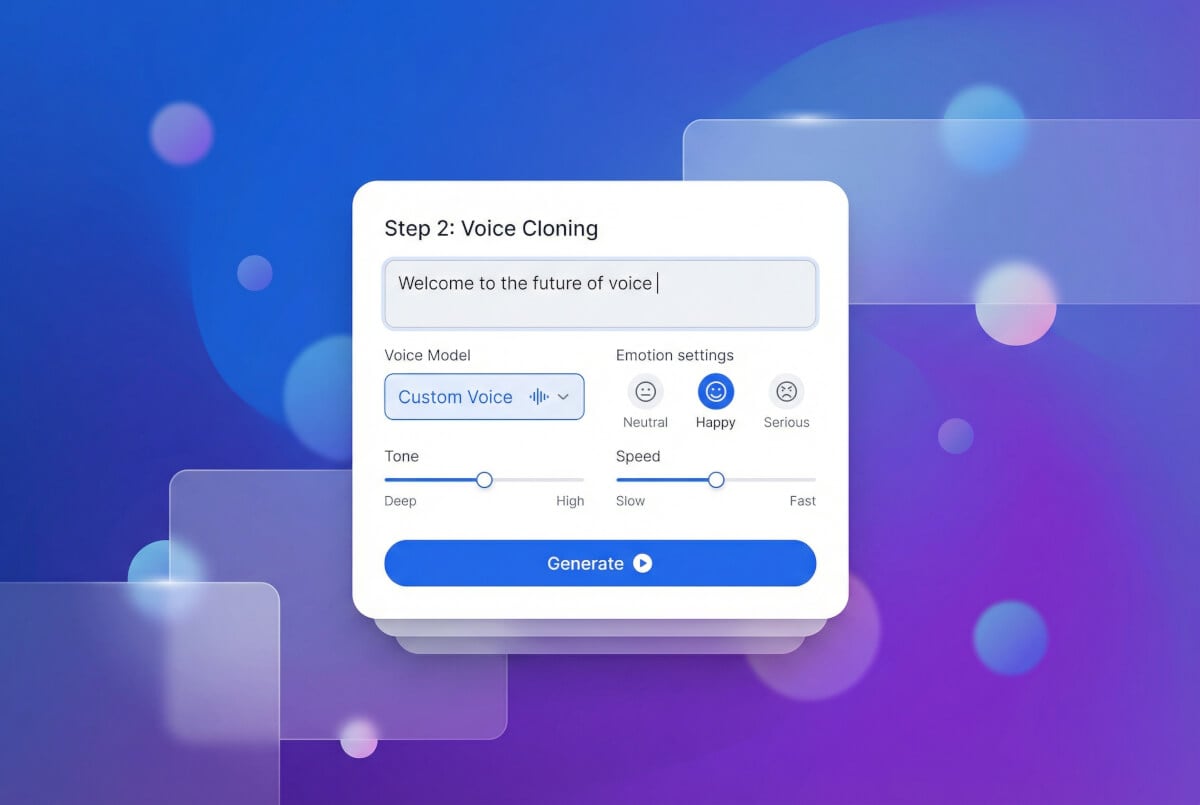
AI 建立語音設定檔
聲音克隆引擎(MiniMax 或 ElevenLabs)處理樣本並產生自訂語音 ID。此 ID 記錄了說話者獨特的聲音特徵,可跨工作階段重複使用。
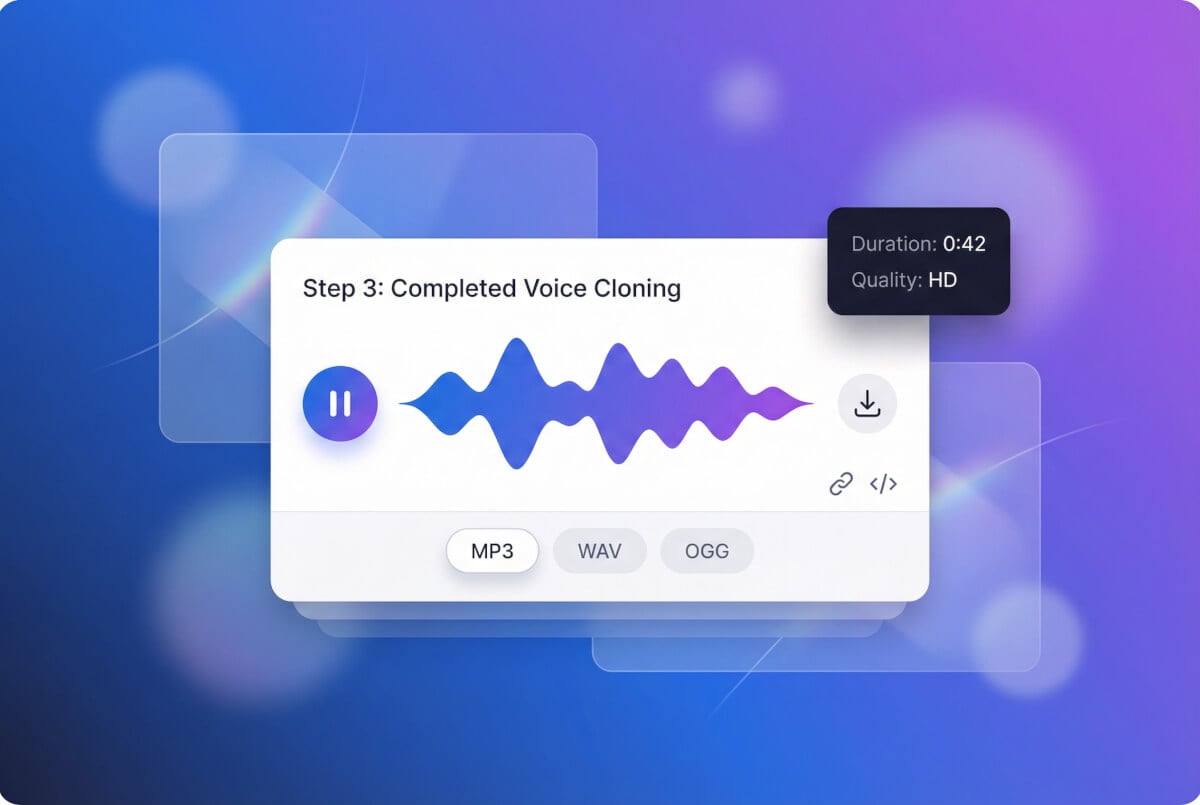
輸入文字,取得語音
輸入任何文字,克隆的聲音會將其朗讀出來。調整語速、音高、情緒和穩定性,以 MP3 格式下載。可反覆調整設定重新生成,直到滿意為止。
常見問題
AI 聲音克隆的原理是什麼?
提供目標聲音的音訊樣本後,AI 模型會分析語音特徵並建立語音設定檔(自訂語音 ID)。輸入文字時,文字轉語音引擎使用該設定檔生成與原始說話者聲音相符的語音。
支援哪些音訊格式?樣本需要多長?
支援 MP3、WAV 和 M4A 格式。最少需要幾秒鐘清晰的語音。較長的樣本有助於提升準確度,但系統會自動執行降噪和標準化處理,即使錄音品質不完美也能使用。ElevenLabs 還支援多個樣本檔案以獲得更高保真度。
AI 聲音克隆免費嗎?
建立帳號時會獲得免費額度。這些額度可用於聲音克隆和文字轉語音生成。本服務採用額度制,實際用量取決於使用的模型和輸出長度。請在帳號頁面查看目前的額度餘額。
支援哪些語言?
TTS 引擎支援多種語言。你可以克隆一種語言的聲音,然後生成其他語言的語音。MiniMax、ElevenLabs 和 Gemini TTS 各自原生處理不同的語言集合。
聲音克隆和普通文字轉語音有什麼不同?
普通文字轉語音使用模型內建的預設聲音。聲音克隆則從你的音訊樣本建立新的語音設定檔,因此輸出聽起來像特定的人,而非通用的 AI 語音。克隆的聲音還能調整音高、語速、情緒等參數。
我的語音資料安全嗎?
語音樣本用於建立語音 ID 及生成語音輸出。平台不會將你的語音資料用於訓練公開模型。關於資料處理的具體細節,請參閱平台的隱私政策。