
โคลนเสียง AI
อัปโหลดตัวอย่างเสียง แล้ว AI จะวิเคราะห์และโคลนเสียงของผู้พูด ใช้เสียงที่โคลนแล้วอ่านข้อความอะไรก็ได้ รองรับหลายเอนจิน ทั้ง MiniMax และ ElevenLabs สมัครเพื่อรับเครดิตฟรี
ทำอะไรได้บ้างด้วยโคลนเสียง AI

โคลนเสียงใครก็ได้จากตัวอย่างสั้นๆ
อัดเสียงพูดไม่กี่วินาทีหรืออัปโหลดไฟล์เสียงที่มีอยู่ AI จะวิเคราะห์ลักษณะเสียง ได้แก่ โทนเสียง จังหวะ และระดับเสียง แล้วสร้างโปรไฟล์เสียงที่ใช้ซ้ำได้ ทั้ง MiniMax และ ElevenLabs รองรับการโคลนทันทีจากตัวอย่างเดียว ระบบจะลดเสียงรบกวนอัตโนมัติเพื่อทำความสะอาดเสียงก่อนเข้าสู่กระบวนการโคลน
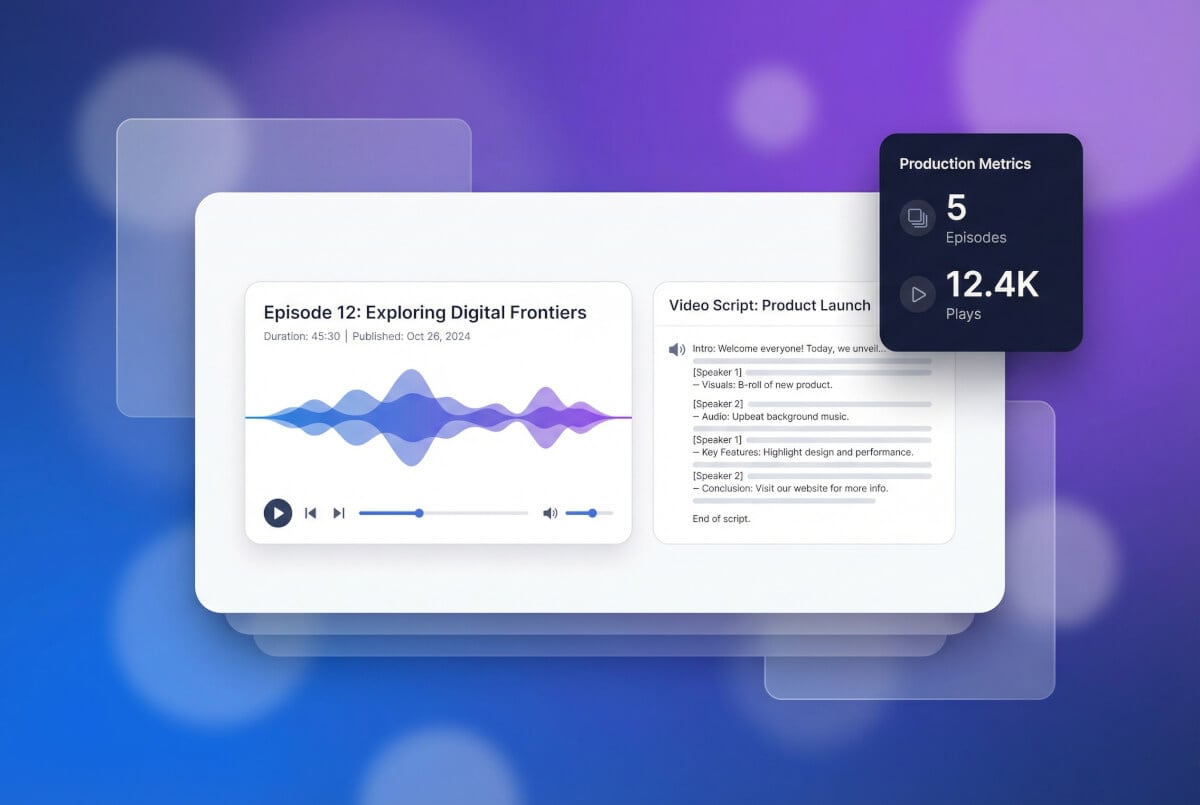
สร้างเสียงพากย์และเสียงบรรยาย
เมื่อมีเสียงโคลนแล้ว เพียงพิมพ์ข้อความก็จะได้ไฟล์เสียงในเสียงนั้น ใช้สำหรับพากย์วิดีโอ อินโทรพอดแคสต์ เนื้อหาอธิบาย หรือเดโมผลิตภัณฑ์ ปรับความเร็ว ระดับเสียง และอารมณ์ให้เข้ากับบริบทได้ ส่งออกเป็นไฟล์ MP3 พร้อมดาวน์โหลดทันที

พูดหลายภาษาด้วยเสียงของคุณเอง
เอนจิน TTS ที่อยู่เบื้องหลังโคลนเสียง ได้แก่ MiniMax, ElevenLabs และ Gemini TTS แต่ละตัวรองรับหลายภาษาแบบเนทีฟ คุณสามารถใช้โปรไฟล์เสียงที่โคลนไว้สร้างเสียงพูดในภาษาอื่นได้ เหมาะสำหรับครีเอเตอร์ที่ผลิตคอนเทนต์สำหรับผู้ชมหลายภูมิภาค
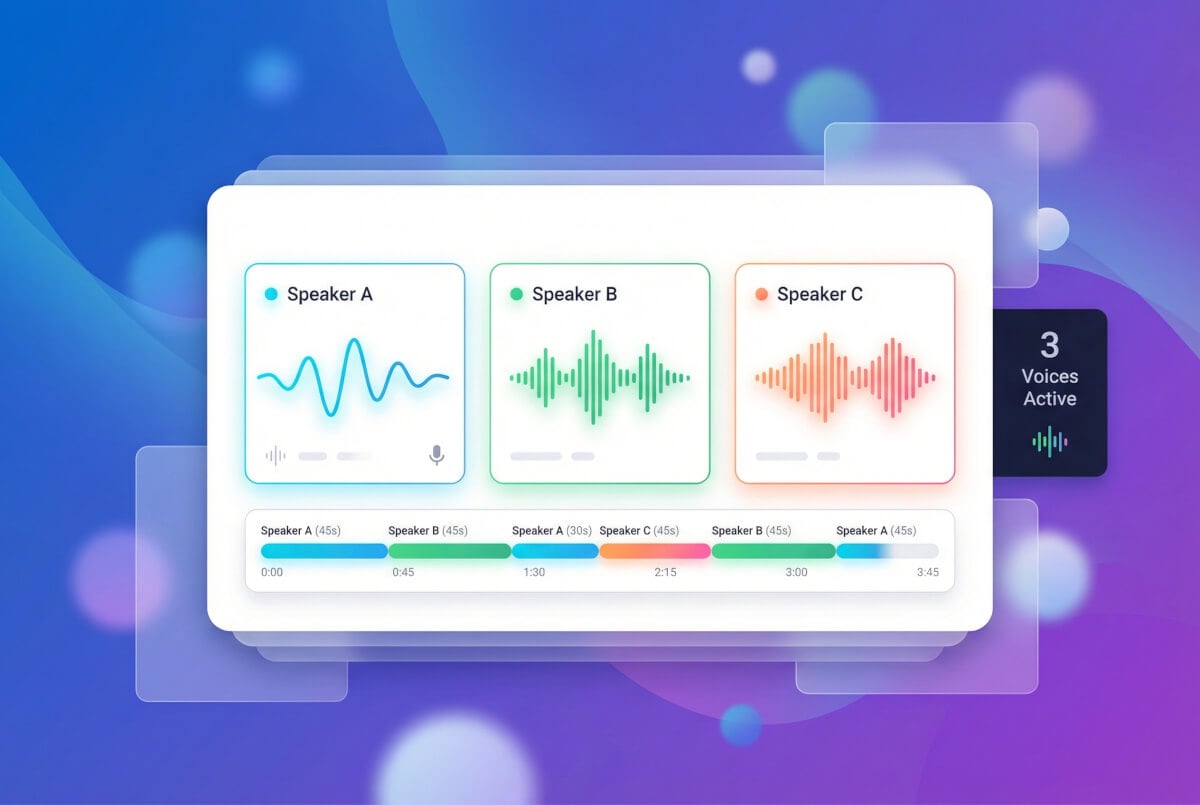
สร้างบทสนทนาด้วยหลายเสียง
โคลนเสียงหลายเสียงแล้วกำหนดให้ผู้พูดแต่ละคนในสคริปต์ ระบบหลายผู้พูดจะให้ ID เฉพาะแต่ละเสียง คุณจึงสร้างบทสนทนา คอนเทนต์แบบสัมภาษณ์ หรือหนังสือเสียงที่แต่ละตัวละครมีเสียงเฉพาะได้ พารามิเตอร์ของผู้พูดแต่ละคน ทั้งความเร็ว ระดับเสียง และความเสถียร ตั้งค่าแยกกันได้
วิธีใช้งาน — สามขั้นตอน

อัปโหลดตัวอย่างเสียง
เตรียมไฟล์เสียงของเสียงที่ต้องการโคลน เสียงพูดชัดเจนไม่กี่วินาทีก็เพียงพอ ระบบจะลดเสียงรบกวนและปรับระดับเสียงให้สม่ำเสมออัตโนมัติ เพื่อให้สัญญาณเสียงสะอาด
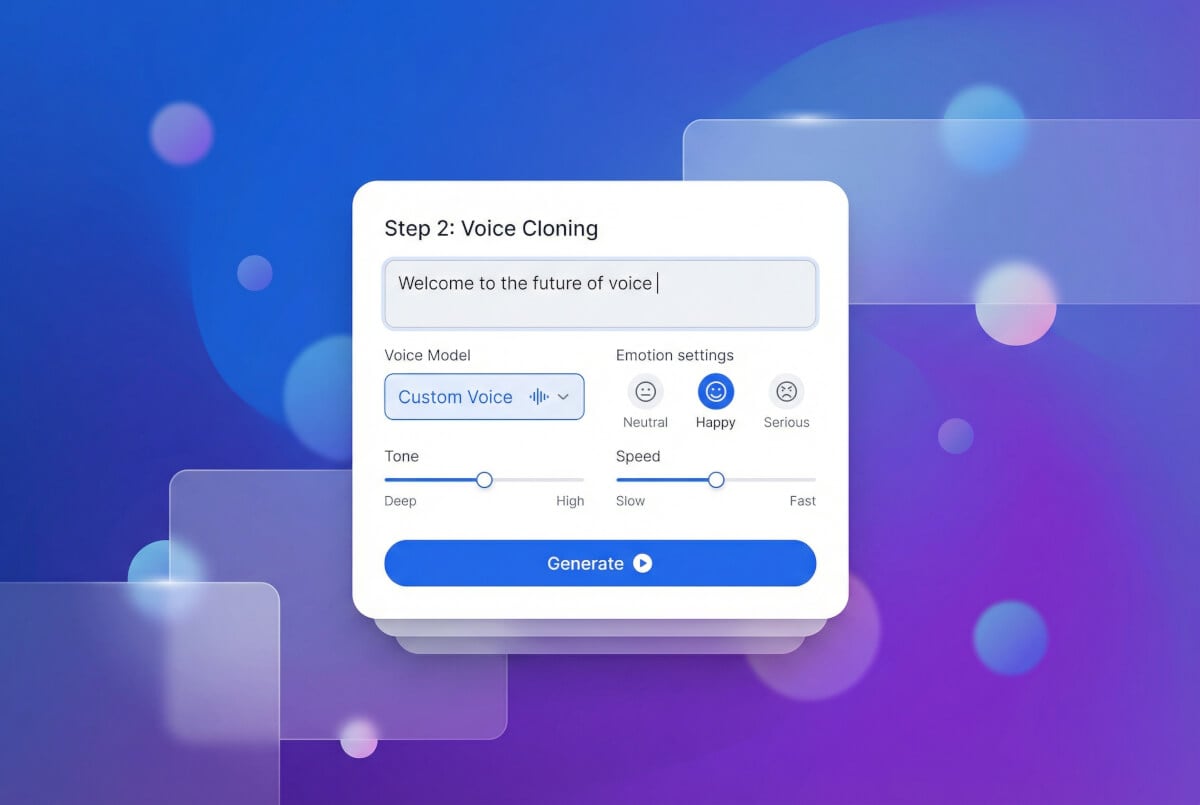
AI สร้างโปรไฟล์เสียง
เอนจินโคลนเสียง (MiniMax หรือ ElevenLabs) ประมวลผลตัวอย่างและสร้าง Voice ID เฉพาะ ID นี้บันทึกลักษณะเสียงเฉพาะของผู้พูดและนำกลับมาใช้ซ้ำข้ามเซสชันได้
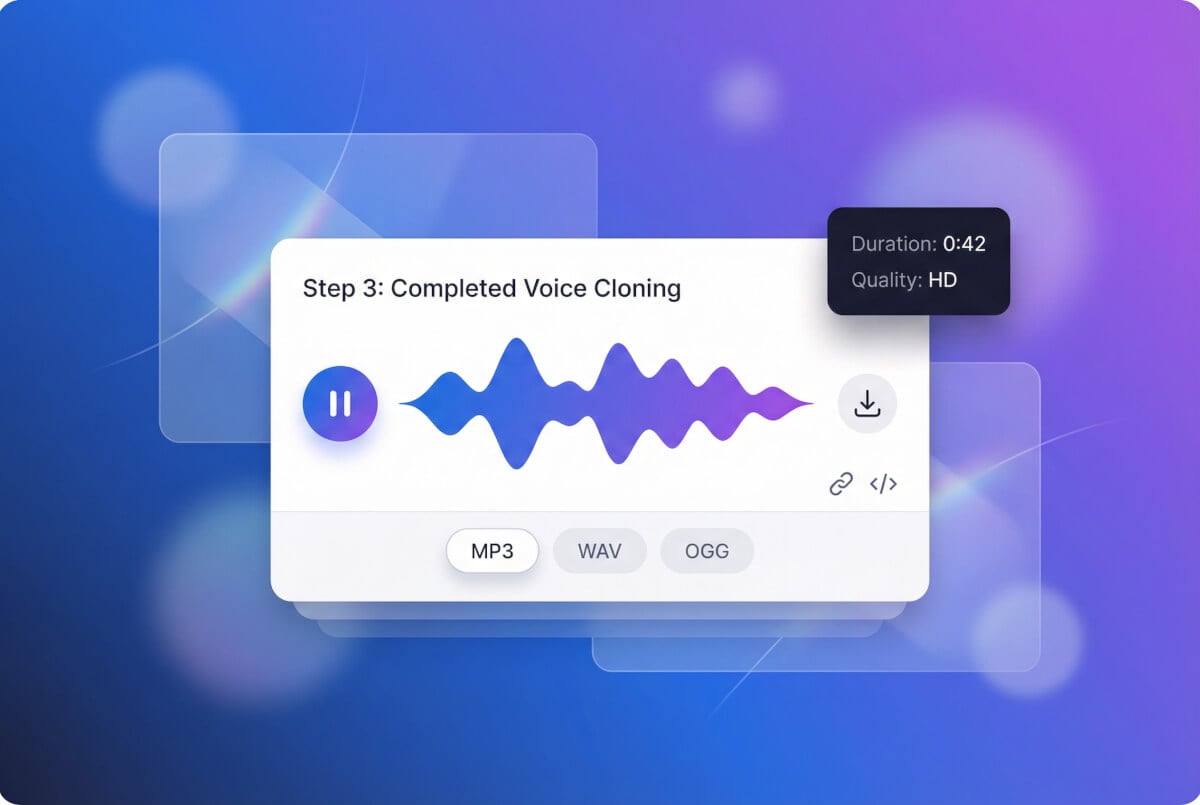
พิมพ์ข้อความ รับเสียงพูด
พิมพ์ข้อความอะไรก็ได้ แล้วเสียงที่โคลนจะอ่านให้ ปรับความเร็ว ระดับเสียง อารมณ์ และความเสถียร ดาวน์โหลดเป็น MP3 สร้างใหม่ด้วยการตั้งค่าต่างๆ จนกว่าจะพอใจ
คำถามที่พบบ่อย
โคลนเสียง AI ทำงานอย่างไร?
คุณอัปโหลดตัวอย่างเสียงของเสียงเป้าหมาย โมเดล AI จะวิเคราะห์ลักษณะเสียงและสร้างโปรไฟล์เสียง (Voice ID เฉพาะ) เมื่อพิมพ์ข้อความ เอนจิน TTS จะใช้โปรไฟล์นั้นสร้างเสียงพูดที่ตรงกับเสียงต้นฉบับ
รองรับไฟล์เสียงรูปแบบไหน และตัวอย่างต้องยาวเท่าไหร่?
รองรับ MP3, WAV และ M4A เสียงพูดชัดเจนไม่กี่วินาทีคือขั้นต่ำ ตัวอย่างที่ยาวกว่าช่วยเพิ่มความแม่นยำได้ แต่ระบบจะลดเสียงรบกวนและปรับมาตรฐานอัตโนมัติ จึงใช้ได้แม้การอัดเสียงไม่สมบูรณ์ ElevenLabs ยังรองรับหลายไฟล์ตัวอย่างเพื่อความแม่นยำที่สูงขึ้น
โคลนเสียง AI ใช้ฟรีไหม?
คุณจะได้รับเครดิตฟรีเมื่อสร้างบัญชี เครดิตเหล่านี้ใช้สำหรับโคลนเสียงและสร้างเสียงพูดจากข้อความ ระบบเป็นแบบเครดิต ปริมาณการใช้งานขึ้นอยู่กับโมเดลและความยาวของเสียงที่สร้าง ตรวจสอบเครดิตคงเหลือได้ในหน้าบัญชี
รองรับภาษาอะไรบ้าง?
เอนจิน TTS รองรับหลายภาษา คุณสามารถโคลนเสียงจากภาษาหนึ่งแล้วสร้างเสียงพูดในภาษาอื่นได้ MiniMax, ElevenLabs และ Gemini TTS แต่ละตัวรองรับชุดภาษาของตัวเอง
โคลนเสียงต่างจาก TTS ปกติอย่างไร?
TTS ปกติใช้เสียงสำเร็จรูปที่ฝังอยู่ในโมเดล โคลนเสียงจะสร้างโปรไฟล์เสียงใหม่จากตัวอย่างเสียงของคุณ ทำให้ผลลัพธ์ฟังดูเหมือนคนจริงๆ ไม่ใช่เสียง AI ทั่วไป เสียงที่โคลนแล้วยังปรับพารามิเตอร์ได้ทั้งระดับเสียง ความเร็ว และอารมณ์
ข้อมูลเสียงของฉันปลอดภัยไหม?
ตัวอย่างเสียงถูกนำไปใช้สร้าง Voice ID และสร้างเสียงพูดเท่านั้น แพลตฟอร์มไม่นำข้อมูลเสียงของคุณไปฝึกโมเดลสาธารณะ สำหรับรายละเอียดการจัดการข้อมูล โปรดดูนโยบายความเป็นส่วนตัวของแพลตฟอร์ม