
AI 声音克隆
上传一段语音样本,AI 即可分析并复制说话者的声音特征,用克隆出的声音朗读任何文字。支持 MiniMax、ElevenLabs 等多种引擎。注册即送免费额度。
声音克隆能做什么

从短音频复制任何声音
录制几秒钟的语音,或上传现有音频文件。AI 会分析声音的音色、节奏、音高等特征,构建可重复使用的语音配置文件。MiniMax 和 ElevenLabs 都支持从单个样本即时克隆。系统自动进行降噪处理,在克隆前清理输入音频。
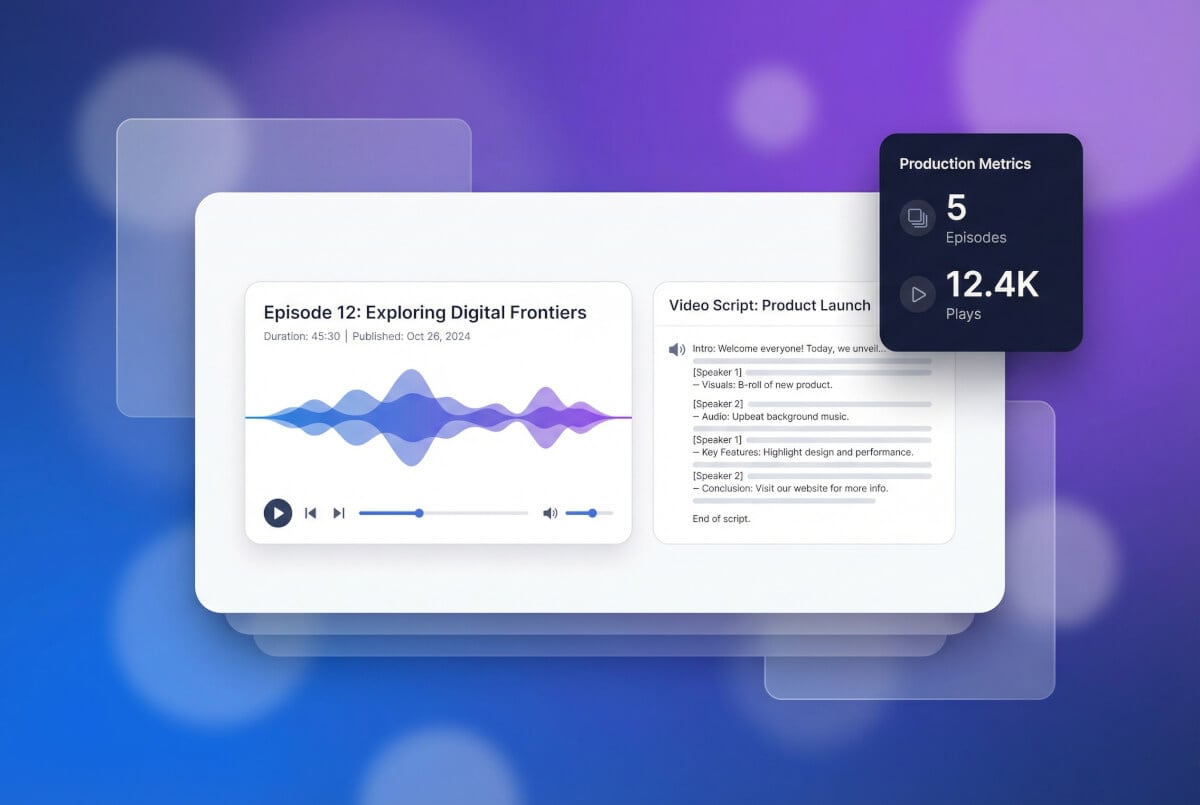

用自己的声音说多种语言
声音克隆背后的 TTS 引擎(MiniMax、ElevenLabs、Gemini TTS)各自原生支持多种语言。你可以用克隆的语音配置文件生成不同语言的语音。适合面向多个地区制作内容的创作者。
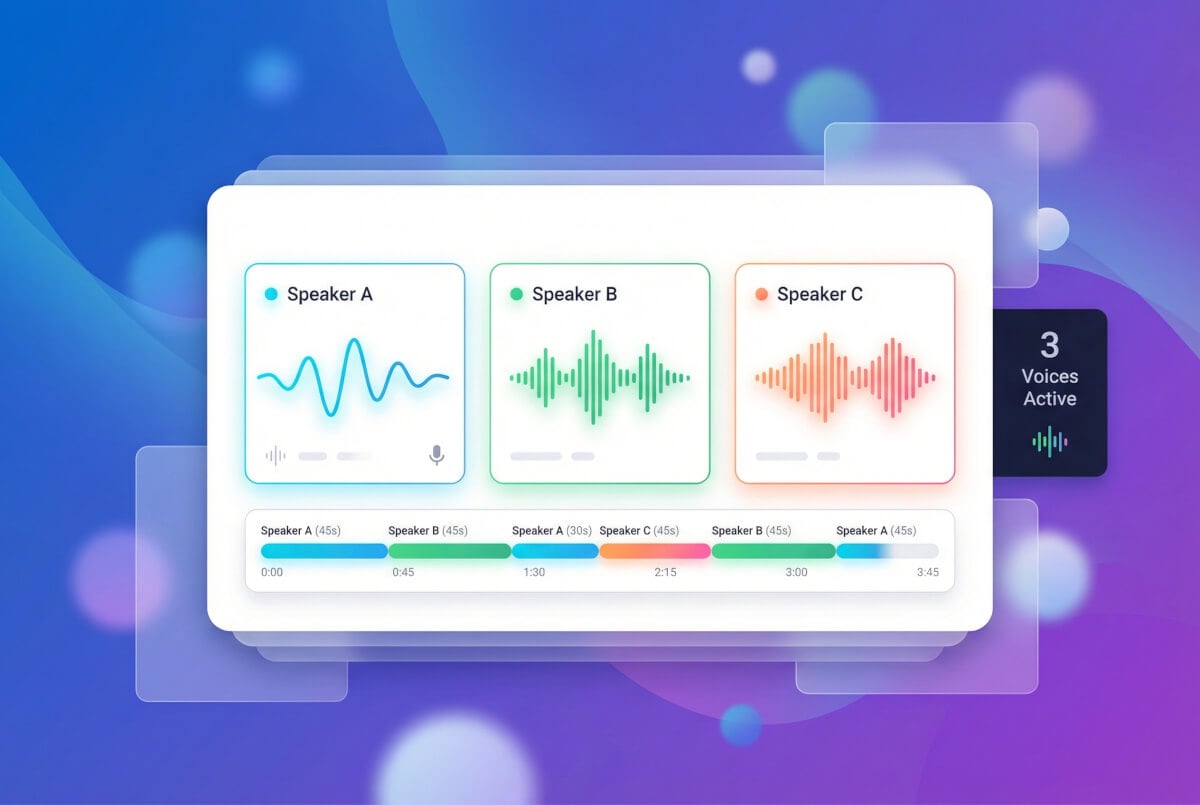
用多种声音构建对话
克隆多个声音并分配给脚本中的不同说话者。多讲者系统为每个声音分配独立 ID,让你构建对话内容、访谈形式或有声书旁白,每个角色都有独特的声音。每位说话者的语速、音高、稳定性参数各自独立。
使用流程 — 三个步骤

上传语音样本
准备要克隆的声音音频文件。几秒钟清晰的语音即可。系统会自动进行降噪和音量标准化,确保输入信号干净。
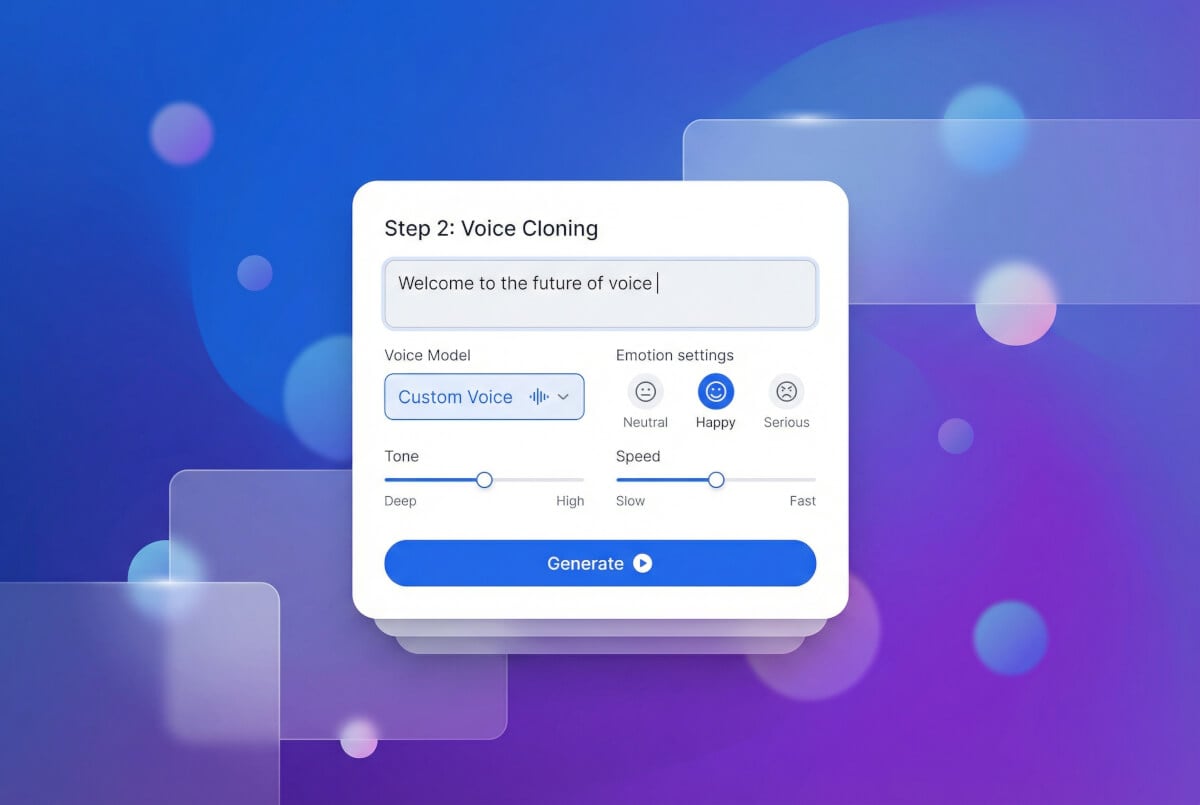
AI 创建语音配置文件
声音克隆引擎(MiniMax 或 ElevenLabs)处理样本并生成自定义语音 ID。此 ID 记录了说话者独特的声音特征,可跨会话重复使用。
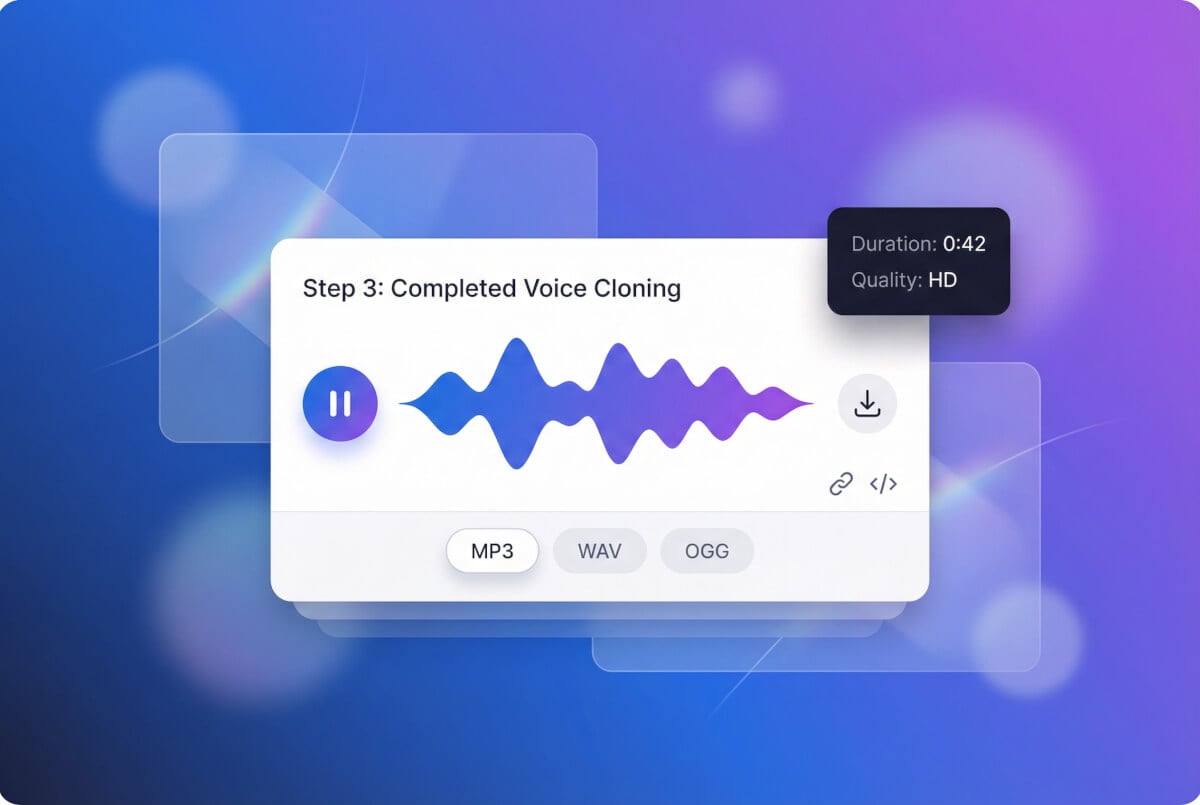
输入文字,获取语音
输入任意文字,克隆的声音会将其朗读出来。调整语速、音高、情绪和稳定性,以 MP3 格式下载。可反复调整设定重新生成,直到满意为止。
常见问题
AI 声音克隆的原理是什么?
提供目标声音的音频样本后,AI 模型会分析语音特征并创建语音配置文件(自定义语音 ID)。输入文字时,文字转语音引擎使用该配置文件生成与原始说话者声音相符的语音。
支持哪些音频格式?样本需要多长?
支持 MP3、WAV 和 M4A 格式。最少需要几秒钟清晰的语音。较长的样本有助于提升准确度,但系统会自动执行降噪和标准化处理,即使录音质量不完美也能使用。ElevenLabs 还支持多个样本文件以获得更高保真度。
AI 声音克隆免费吗?
创建账号时会获得免费额度。这些额度可用于声音克隆和文字转语音生成。本服务采用额度制,实际用量取决于使用的模型和输出长度。请在账号页面查看当前的额度余额。
支持哪些语言?
TTS 引擎支持多种语言。你可以克隆一种语言的声音,然后生成其他语言的语音。MiniMax、ElevenLabs 和 Gemini TTS 各自原生处理不同的语言集合。
声音克隆和普通文字转语音有什么不同?
普通文字转语音使用模型内置的预设声音。声音克隆则从你的音频样本创建新的语音配置文件,因此输出听起来像特定的人,而非通用的 AI 语音。克隆的声音还能调整音高、语速、情绪等参数。
我的语音数据安全吗?
语音样本用于创建语音 ID 及生成语音输出。平台不会将你的语音数据用于训练公开模型。关于数据处理的具体细节,请参阅平台的隐私政策。